The Dalton Cycle
Fri 29 July 2016
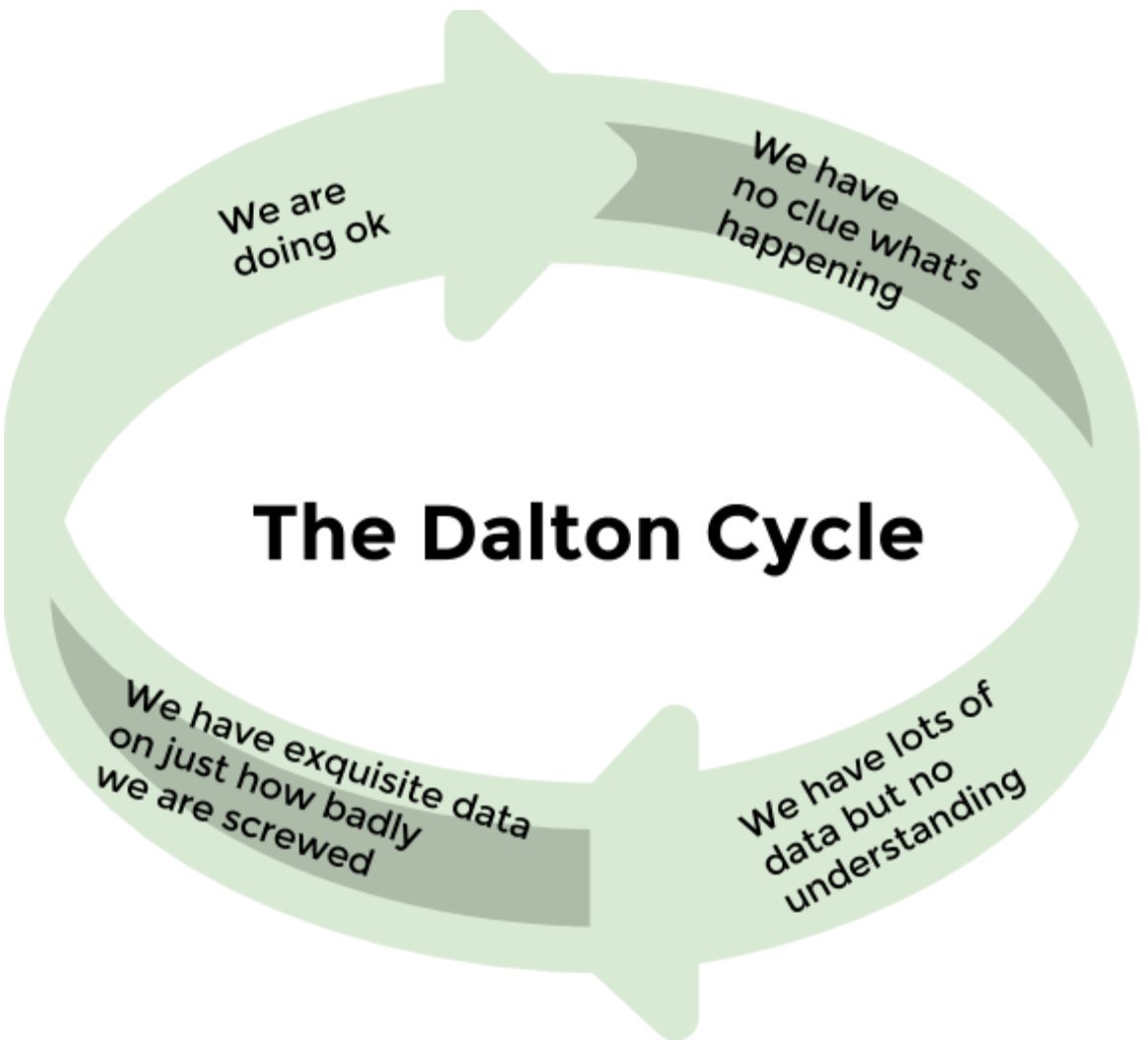
Thanks to Niall Dalton for this comment at the end of his post on the trustable-software list
"I go off on this tangent to raise the whole bucket of pain involved in building a trustworthy system like this. Not that we necessarily want to try to build a 100% trustworthy system. Life gets a /lot/ easier if we tolerate a little slop rather than demanding perfection.
Which is not to say that systems designers shouldn't learn a bit more combinatorics, probability and statistics.. e.g. you may have imagined randomly distributing chunks of data across the cluster above, and imagine it relatively unlikely to lose data in some major outage. E.g. take a genuine large outage where 1% of the 1000 machine cluster is irrevocably lost and you do random r=3 replication. It's 99.7% that you've lost all 3 copies of some piece of data. (Breaking the cluster into replication sets where the number of combinations chosen for placement of replicas can get that down to 0.02%). Some services learned this the hard way, going through the transition of
'we have no clue what's happening' -> 'we have lots of data but no understanding' -> 'oh bugger, we have exquisite data on just how badly we're screwed" -> "practically speaking, we're doing ok'.
But most systems I look at are disturbingly early in the cycle."
Reposted from LinkedIn